Topic outline
- General
- Topik 1: Pengantar Statistika
Topik 1: Pengantar Statistika
Definisi:
Statistik : Sajian narasi situasi atau penelitian dalam bentuk data dalam angka atau bukan.
Statistika : Ilmu yang mempelajari tentang penggunaan dan analysis data
Statistik terbagi dua :
Statistik Deskriptif : Statistik naratif, gambaran situasi
Statistik Inferensial : Statistik yang digunakan untuk pengolahan dan analisis data
- Topik 2: Populasi Dan Sampel
Topik 2: Populasi Dan Sampel
Populasi : Kumpulan Entitas dalam suatu lingkungan dengan karakter yang homogen
Sampel: Bagian dari populasi yang dianggap mewakili ciri/karakter populasi.
Teknik pengambilan sampel.
- Topik 3: Pengukuran Terpusat
Topik 3: Pengukuran Terpusat
Pengukuran Terpusat:
Pengukuran Terpusat adalah pengukuran dengan data tunggal
Pengukuran terse but adalah:
1. Mean atau rata-rata
Yaitu jumlah akumulasi seluruh data dibagi dengan banyak data.
2. Median atau nilai tengah
Yaitu nilai tengah pada urutan data dari yang terkecil hingga terbesar atau sebaliknya.
3. Modus atau data terbanyak dengan nilai yang sama
Yaitu data yang nilainya paling sering mucul.
- Topik 4: Pengukuran Kelompok I
Topik 4: Pengukuran Kelompok I
Pengukuran Data Kelompok
1) Range : Rentang Data
Jarak antara data tertingi dan data terendah
R = Data terbesar-Data terkecil
2) Banyak kelas yang akan dibuat (K).
K = 1 + 3,33 log N
Dimana:
K= banyak kelas yang akan dibuat
N= banyaknya data
3) Menentukan jarak interval kelas tau Panjang Kelas
P = R/K
P = Panjang Kelas
R = Rentang Data
K= Banyak kelasTugas 4 Statistik DATA KELOMPOK Assignment
- Topik 5: Pengukuran Kelompok II (Mean, Modus, Kuartil, dan Median)
Topik 5: Pengukuran Kelompok II (Mean, Modus, Kuartil, dan Median)
Topik 5: Pengukuran Kelompok II (Mean, Modus, Kuartil, dan Median)
Pada data berkelompok, mean, modus, dan median didapat dengan rumus yang berbeda dengan rumus pada data tunggal.
Pada Topik ini kita akan belajar menghitung beberapa pengukuran dalam data berkelompok, yaitu:
Mean
Modus
Kuartil
Median
- Topik 6: Pengukuran Kelompok III
- Topik 7: Latihan Soal
Topik 7: Latihan Soal
Latihan Soal
1. Berikan contoh data nominal dan data interval masing-mainsg 2
2. Apa yang disebut data diskrit?
3. Apa arti probability sampling?
4. Sebutkan jenis-jenis non probability sampling
5. Diketahui data sebagai berikut: 9.5, 7, 7.5, 8, 5, 6, 6, 8, 6.5, 6
cari mean, median, dan modusnya
6. Diketahui data kelompok sebagai berikut,
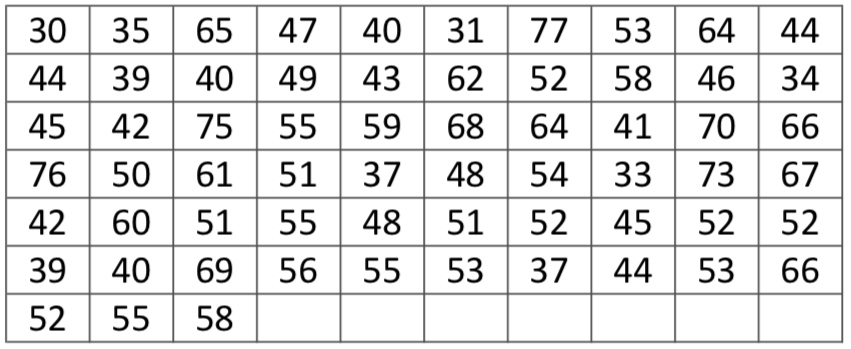
soal :
1. Buat tabel frekwensi nya
2. mean, modus, kuartil dan median
3. SD dan varians untuk populasi nya
- Topik 8: UTS
Topik 8: UTS
UTS
Jawab Soal pada Sub Topik sesuai kelasnya
- Topik 9: Hipotesa
Topik 9: Hipotesa
Hipotesa
hipotesa dapat diartikan secara sederhana sebagai dugaan atau jawaban sementara
Hipotesis berasal dari bahasa Yunani hypo yang berarti
di bawah dan thesis yang berarti pendirian, pendapat yang ditegakkan, kepastian. Jika
dimaknai secara bebas, maka hipotesis berarti pendapat yang kebenarannya masih diragukan.
Untuk bisa memastikan kebenaran dari pendapat tersebut, maka suatu hipotesis harus diuji
atau dibuktikan kebenarannya.
Untuk membuktikan kebenaran suatu hipotesis, seorang peneliti dapat dengan sengaja
menciptakan suatu gejala, yakni melalui percobaan atau penelitian. Jika sebuah hipotesis
telah teruji kebenarannya, maka hipotesis akan disebut teori.
Dalam penelitian ada dua jenis hipotesis yang seringkali harus dibuat oleh peneliti, yakni
hipotesis penelitian dan hipotesis statistik. Pengujian hipotesis penelitian merujuk pada
menguji apakah hipotesis tersebut betul-betul terjadi pada sampel yang diteliti atau tidak. Jika
apa yang ada dalam hipotesis benar-benar terjadi, maka hipotesis penelitian terbukti, begitu
pun sebaliknya. Sementara itu, pengujian hipotesis statistik berarti menguji apakah hipotesis
penelitian yang telah terbukti atau tidak terbukti berdasarkan data sampel tersebut dapat
diberlakukan pada populasi atau tidak.
- Topik 10 : Uji Hipotesis Asosiatif
Topik 10 : Uji Hipotesis Asosiatif
PENGUJIAN HIPOTESIS ASOSIATIF
Hipotesis asosiatif merupakan dugaan adanya hubungan antar variabel dalam populasi, melalui data hubungan dalam sampel. Untuk itu, dalam langkah awal pembuktiannya, perlu dihitung terlebih dulu koefisien korelasi antar variabel dalam sampel, kemudian koefisien yang ditemukan tersebut diuji signifikansinya. Jadi menguji hipotesis asosiatif adalah menguji koefisien korelasi yang ada pada sampel untuk diberlakukan pada seluruh populasi tempat sampel diambil.
Terdapat tiga macam hubungan antar variabel, yaitu hubungan simetris, hubungan sebab akibat (kausal), dan hubungan interaktif (saling mempengaruhi). Untuk mencari hubungan antara dua variabel atau lebih dilakukan dengan menghitung koefisien korelasi antara variabel-variabel tersebut. Koefisien korelasi merupakan angka yang menunjukkan arah dan kuatnya hubungan antar variabel. Arah hubungan dinyatakan dengan tanda positif atau negatif, sedangkan kuatnya hubungan ditunjukkan dengan besarnya angka koefisien korelasi yang besarnya berkisar antara 0 sampai dengan ±1.
Hubungan positif antara dua variabel memberikan arti bahwa naiknya salah satu
variabel akan menyebabkan naiknya variabel yang satunya. Sedangkan hubungan yang negatif mengandung arti bahwa ketika salah satu variabel nilainya naik maka variable yang lain turun.
Sebagai hubungan yang positif antara besarnya pendapatan dengan besarnya belanja bulanan, mengandung arti bahwa ketika pendapatan naik, maka belanja bulanan juga semakin naik. Sedangkan hubungan negatif terjadi misalnya dalam hubungan antara faktor usia dengan daya ingat, yang berarti bahwa semakin
bertambah usia seseorang maka daya ingat akan semakin menurun. Demikian juga sebalknya.
Angka koefisien korelasi yang berkisar antara 0 sampai dengan ±1 menujukkan kuat/lemahnya hubungan kedua variabel tersebut. Koefisien korelasi +1 menunjukkan bahwa antara kedua variabel tersebut terdapat hubungan positif sempurna. Sempurna disini mengandung arti bahwa naik atau turunnya salah satu variabel bisa dijelaskan dengan variabel yang lain dengan sepenuhnya tanpa kesalahan sedikitpun. Sedangkan koefisien korelasi sebesar nol, berarti bahwa antara kedua variabel tersebut sama sekali tidak terdapat hubungan. Artinya, naik atau turunnya variabel yang satu sama sekali tidak mempengaruhi variabel yang lain. Namun, dalam kehidupan sosial, korelasi sebesar nol dan satu ini jarang sekali terjadi (tidak pernah ada).
Dalam analisis statistik, besarnya koefisien korelasi bisa digambarkan dengan penyebaran titik data dalam kurva X-Y. Gambar-gambar yang menunjukkan koefisien korelasi adalah sebagai berikut:
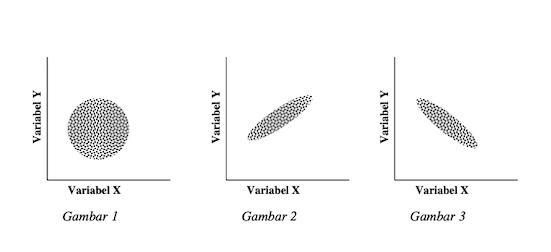
Gambar 1. menunjukkan persebaran hubungan antara variabel X dan variabel Y yang tidak menujukkan pola tertentu. Artinya, pada saat variabel X rendah, variabel Y bisa rendah atau tinggi, demikian juga pada saat variabel X tinggi. Pola seperti ini menujukkan tidak terdapat hubungan antara kedua variabel tersebut.
Gambar 2. menujukkan ketika variabel X rendah maka variabel Y juga rendah. Pada saat variabel X tinggi maka variabel Y juga tinggi. Hubungan seperti ini menunjukkan bahwa antara kedua variabel tersebut terdapat hubungan positif yang cukup kuat.
Gambar 3. menujukkan ketika variabel X rendah maka variabel Y tinggi, dan pada saat variabel X tinggi maka variabel Y rendah. Hubungan seperti ini menunjukkan bahwa antara kedua variabel tersebut terdapat hubungan negatif yang cukup kuat.
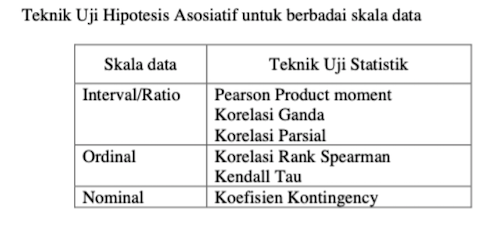
Terdapat bermacam-macam teknik statistik korelasi yang dapat digunakan untuk menguji hipotesis asosiatif. Teknik koefisien yang mana yang akan dipakai tergantung pada jenis data yang dianalisis. Berikut adalah berbagai teknik statistik korelasi yang digunakan untuk menguji hipotesis asosiatif. Uji korelasi untuk data interval dan rasio menggunakan statistik parametriks, sedangkan uji korelasi untuk
data nominal dan ordinal menggunakan statistik nonparametriks.
- Topik 11: Uji Hipotesis Komparatif
Topik 11: Uji Hipotesis Komparatif
PENGUJIAN HIPOTESIS KOMPARATIF
Hipotesis komparasi adalah suatu pengujian dengan cara membandingkan atau dugaan ada tidaknya perbedaan yang signifikan terhadap nilai dua kelompok atau lebih. Jadi, pada hipotesis komparasi hanya sekedar membedakan dan tidak sama sekali memperhatikan hubungan antar variabel. Bila Ho dalam pengujan diterima maka nilai perbandingan dua sampel atau lebih dapat digeneralisasikan untuk seluruh populasi dimana sampel diambil dengan taraf kesalahan tertentu.
Terdapat dua model komparasi yaitu komparasi antara dua sampel dan komparasi lebih dari dua sampel (komparasi k sampel). Selanjutnya setiap model komparasi sampel dibagi menjadi dua jenis yaitu sampel yang berkorelasi dan sampel yang tidak berkorelasi disebut dengan sampel independen.
1. Komparatif Dua Sampel
Pengujian hipotesis komparatif dua sampel yang berkorelasi dan independen dapat menggunakan statistik parametris dan nonpametris. Terdapat 3 macam pengujian komparatif dua sampel, yaitu:
a. Uji Dua Pihak
Uji dua pihak mempunyai bunyi rumusan hipotesis nol dan alternatif yaitu:
Ho : Tidak terdapat perbedaan produktivitas kerja antara pegawai
yang mendapat kendaraan dinas dengan tidak.Ha : Terdapat perbedaan produktivitas kerja antara pegawai
yang mendapat kendaraan dinas dengan tidak.Hipotesis statistiknya
Ho : μ1 = μ2
Ha : μ1 ≠ μ2
b. Uji Pihak Kiri
Uji pihak kiri digunakan apabila rumusan hipotesis nol dan alternatifnya adalah sebagai berikut :
Ho : Prestasi belajar mahasiswa yang masuk sore hari lebih besar atau sama dengan yang masuk pagi hari.
Ha : Prestasi belajar mahsiswa yang masuk sore hari lebih rendah dari yang masuk pagi hari.
Hipotesis statistiknya:
Ho : μ1 ≥ μ2
Ha : μ1 < μ2
c. Uji Pihak Kanan
Uji pihak kanan digunakan bila rumusan hipotesis nol dan alternatifnya berbunyi sebagai berikut :
Ho : Disiplin kerja Pegawai Swasta lebih kecil atau sama dengan Pegawai Negeri.
Ha : Disiplin kerja Pegawai Swasta lebih besar dari Pegawai Negeri.
Atau dapat ditulis dalam bentuk :
Ho : μ1 ≤ μ2
Ha : μ1 > μ2
2. Sampel Berkorelasi
a. Statistik Parametris
t-test
Statistik Parametris yang digunakan untuk menguji hipotesis komparatif rata-rata dua sampel bila datanya berbentuk interval atau ratio menggunakan t-test. Contoh pengujian hipotesisnya yaitu:
Ho : Tidak terdapat perbedaan nilai produktivitas kerja pegawai
antara sebelum dan setelah mendapat kendaraan dinas.Ha : Terdapat perbedaan nilai produktivitas kerja pegawai antara
sebelum dan setelah mendapat kendaraan dinas.b. Statistik Nonparametris
b.1. Mc Nemar Test
Teknik statistik ini digunakan untuk menguji hipotesis komparatif dua sampel yang berkorelasi bila datanya berbentuk nominal atau diskrit. Rancangan penelitian biasanya berbentuk “ before after”. Jadi hipotesis penelitian merupakan perbandingan antara nilai sebelum dan sesudah ada perlakuan /treatment. Test Mc Nemar berdistribusi Chi Kuadrat ( λ2 ). Contoh pengujian Hipotesisnya yaitu:
Ho : Tidak terdapat perubahan (perbedaan) penjualan sebelum dan
sesudah ada sponsor.Ha : Terdapat perubahan penjualan sebelum dan sesudah ada
sponsor.b.2. Sign Test (Uji Tanda)
Sign test digunakan untuk menguji hipotesis komparatif dua sampel yang berkorelasi, bila datanya berbentuk ordinal. Teknik ini dinamakan uji tanda (sign test) karena data yang akan dianalisis dinyatakan dalam bentuk tanda-tanda, yaitu tanda positif dan negatif. Misalnya dalam suatu eksperimen, hasilnya tidak dinyatakan berapa besar perubahanya secara kuantitatif, tetapi dinyatakan dalam bentuk perubahan yang positif dan negatif.
Hipotesis nol (Ho) yang diuji adalah : p (XA > XB ) = P (XA < XB ) = 0,5. Peluang berubah dari XA ke XB = peluang berubah dari XB ke XA = 0,5, atau peluang untuk memperoleh beda yang bertanda positif sama dengan peluang untuk memperoleh beda yang negatif. Jadi kalau tanda positif jauh lebih banyak dari negatifnya, dan sebaliknya, maka Ho ditolak. XA = nilai setelah ada perlakuan (treatment) dan XB = nilai sebelum ada kelompok yang diobservasi. Bila jarak antara median dengan tanda positif dan negatif sama nol, maka Ho diterima. Contoh pengajuan Hipotesisnya yaitu:
Ho : Tidak terdapat perbedaan pengaruh yang signifikan inssentif terhadap kesejahteraan keluarga baik menurut suami maupun istri.
Ha : Terdapat pengaruh positif dan signifikan kenaikan insentif yang diberikan oleh perusahaan terhadap kesejahteraan keluarga baik menurut suami maupun isteri.
b.3. Wilcoxon Match Pairs Test
Teknik ini merupakan penyempurnaan dari uji tanda. Kalau dalam uji tanda besarnya selisih nilai angka antara positif dan negatif tidak diperhitungkan, sedangkan dalam uji Wilcoxon ini diperhitungkan. Seperti dalam uji tanda, teknik ini digunakan untuk menguji hipotesis komparatif dua sampel yang berkorelasi bila datanya berbentuk ordinal (berjenjang). Contoh pengujian hipotesisnya:
Ho :AC tidak berpengaruh terhadap produktivitas kerja
pegawai.Ha :AC berpengaruh terhadap produktivitas kerja pegawai.
3. Sampel Independen (Tidak Berkorelasi)
Menguji hipotesis dua sampel independen adalah menguji kemampuan generalisasi rata–rata data dua sampel yang tidak berkorelasi. Misalnya perbandingan penghasilan petani dan nelayan, disiplin kerja pegawai negeri dan swasta. Teknik statistik yang digunakan untuk menguji hipotesis komparatif, tergantung jenis datanya. Teknik statistik t-test adalah merupakan teknik statistik parametris yang digunakan untuk menguji komparasi data ratio atau interval, sedangkan statistik nonparametris yang dapat digunakan adalah: median test , mann-Whitney, kolmogorov smirnov, fisher exact, chi kuadrat, test run wald-Wolfowitz. Statistik nonparametris digunakan untuk menguji hipotesis bila datanya nominal dan ordinal.
a. Statistik Parametris
t-test
baca sub topik 1
b. Statistik Nonparametris
b.1 Chi Kuadrat (λ2) dua sampel
Chi kuadrat digunakan untuk menguji hipotesis komparatif dua sampel bila datanya berbetuk nominal dan sampelnya besar. Cara perhitungan dapat menggunakan rumus yang telah ada, atau dapat menggunakan tabel kontingensi 2 x 2 (dua baris x dua kolom ).
Kelompok
Tingkat pengaruh perlakuan
Jumlah sampel
Berpengaruh
Tidak berpengaruh
Kelompok eksperimen
a
b
a+b
Kelompok kontrol
c
d
C+d
Jumlah
a+c
b+d
n
contoh soal pada link ini ; https://www.statistikian.com/2012/11/rumus-chi-square.html
b.2 Fisher Exact Probability Test
Test ini digunakan untuk menguji signifikansi hipotesis komparatif dua sampel kecil independen bila datanya berbentuk nominal. Uji Fisher merupakan suatu tehnik untuk menganalisa data diskrit (nominal atau ordinal) ketika dua sampel independen adalah kecil
b.3 Test Median (Median Test)
Test median digunakan untuk menguji signifikansi hipotesis komparatif dua sampel independen bila datanya berbrntuk nominal atau ordinal. Pengujian didasarkan atas median dari sampel yang diambil secara random. Dengan demikian Ho yang akan diuji berbunyi: tidak terdapat perbedaan dua kelompok populasi berdasarkan mediannya.Untuk menggunakan test median, maka pertama–tama harus dihitung gabungan dua kelompok (median untuk semua kelompok). Selanjutnya dibagi dua, dan dimasukkan ke dalam tabel seperti berikut:
Kelompok
Kel.I
Kel.II
Jumlah
>Median Gabungan
A
B
A+B
≤Median Gabungan
C
D
C+D
Jumlah
A+C=n1
B+D=n2
N=n1 ˧ n2
b.4 Mann-Whitney U-Test
U Test ini digunakan unutuk menguji hipotesis komparatif dua sampel independen bila datanya berbentuk ordinal. Bila dalam suatu pengamatan data berbentuk interval, maka perlu dirubah dulu ke dalam data ordinal. Bila data masih berbentuk interval, sebenarnya dapat menggunakan t-test untuk pengujiannya, tetapi bila asumsi t-test tidak dipenuhi (misalnya data harus normal), maka test ini dapat digunakan.
Terdapat dua rumus yang digunakan untuk pengujian, digunakan dalam perhitungan, arena akan digunakan untuk mengetahui harga U mana yang lebih kecil. Harga U yang lebih kecil tersebut yang digunakan untuk pengujian dan membandingkan dengan U table.
contoh uji Mann-Whitney bisa dilihat pada link ini:https://statistikceria.blogspot.com/2014/06/contoh-perhitungan-manual-uji-u-mann-whitney.html
b.5 Test Kolmogorov Smirnov Dua Sampel
Test ini digunakan untuk menguji hipotesis komparatif dua sampel independen bila datanya berbentuk ordinal yang telah tersusun pada tabel distribusi frekuensi kumulatif dengan menggunakan kelas-kelas interval. Rumus yang digunakan adalah sebagai berikut:
D= maksimum [Sn1 (X) – Sn2 ( X)]
b.6 Test Run Wald-Wolfowitz
Test ini digunakan untuk menguji signifikansi hipotesis komparatif dua sampel independen bila datanya berbentuk ordinal, dan disusun dalam bentuk run. Oleh karena itu, sebelum data dua sampel (n1 + n2 ) dianalisis maka perlu disusun terlebih dahulu ke dalam bentuk rangking, baru kemudian dalam bentuk run. Kriteria pengujian untuk run test adalah bila run hitung lebih besar atau sama dengan run dari tabel untuk taraf kesalahan tertentu, maka Ho diterima (r hitung ≥ r tabel, Ho diterima).
- Topik 12 : Uji Homogenitas dan Normalitas
Topik 12 : Uji Homogenitas dan Normalitas
Uji Homogenitas dan Normalitas
Uji Normalitas dan uji homogenitas menguji kelayakan data yang bisa digunakan uni hipotesis dalam penelitian.
1. Uji Normaltas
Uji Normalitas sebuah uji yang dilakukan dengan tujuan untuk menilai sebaran data pada sebuah kelompok data atau variabel, apakah sebaran data tersebut berdistribusi normal ataukah tidak. Uji Normalitas dilakukan untuk melihat data yang terkumpul adalah data yang baik atau tidak. Data yang baik mengikuti kurva normal.
Contoh: Apabila instrumen (kuesioner) kurant baik atau responden (sampel) menjawab tidak sesuai (asal-asalan) maka akan terjadi ktidaknormalan data. Salah satu kasus yang bisa kita pahami adalah apabila guru/dosen memberikan soal ujian yang terlalu mudah maka hasil ujian akan relatif sama dengan nilai yang bagus, begitu sebaliknya apabila soal ujian terlalu sulit maka hasil ujian akan yang jelek mendominasi. Apabila kuesioner yang diberikan terlalu menjemukan atau tidak tepat maka hasill kuesioner tidak akan memenuhi kurva normal.
2. Uji Homogenitas
Pengujian homogenitas dimaksudkan untuk memberikan keyakinan bahwa kumpulan data memang berasal dari populasi yang tidak jauh berbeda keragamannya. Pada penelitian terutama eksperimental homogenitas memgang peranan penting agar gangguan dari variabel yang tidak dimasukkan dalam penelitian besarannya tidak signifikant mengganggu fungsi persamaannya.
Contoh: apabila kita meneliti hubungan antara motivasi belajar dan prestasi belajar barus kita pastikan bahwa sampel yang kita miliki relatif sama (homogen) tau tidak mempunyai rentang IQ yang jauh berbeda. Sehingga faktor kesenjangan variabel IQ tidak mengganggu habil penelitian
Model yang sesuai dengan keadaan data adalah apabila simpangan estimasinya mendekati 0. Untuk mendeteksi agar penyimpangan estimasi tidak terlalu besar, maka homogenitas variansi kelompok-kelompok populasi dari mana sampel diambil, perlu diuji. (dalam Matondang, 2012) - Topik 13 : Analisa Regresi
Topik 13 : Analisa Regresi
Analisa Regresi
Analisis Regresi Sederhana
Regresi sederhana didasarkan pada hubungan fungsional ataupun kausal antara satu variabel independen dengan satu variabel dependen.Analisis Regresi Sederhana adalah sebuah metode pendekatan untuk pemodelan hubungan antara satu variabel dependen dan satu variabel independen. Dalam model regresi, variabel independen menerangkan variabel dependennya. Dalam analisis regresi sederhana, hubungan antara variabel bersifat linier, dimana perubahan pada variabel X akan diikuti oleh perubahan pada variabel Y secara tetap. Sementara pada hubungan non linier, perubahaan variabel X tidak diikuti dengan perubahaan variabel y secara proporsional. seperti pada model kuadratik, perubahan x diikuti oleh kuadrat dari variabel x. Hubungan demikian tidak bersifat linier.
Secara matematis model analisis regresi linier sederhana dapat digambarkan sebagai berikut:
Y = A + BX + e
Y adalah variabel dependen atau respon
A adalah intercept atau konstanta
B adalah koefisien regresi atau slope
e adalah residual atau error
Secara praktis analisis regresi linier sederhana memiliki kegunaan sebagai berikut:
1. Model regresi sederhana dapat digunakan untuk forecast atau memprediksi nilai Y. Terlebih dahulu harus dibuat model atau persamaan regresi linier. Ketika model yang fit sudah terbentuk maka model tersebut memiliki kemampuan untuk memprediksi nilai Y berdasarkan variabel Y yang diketahui. Katakanlah sebuah model regresi digunakan untuk membuat persamaan antara pendapatan (X) dan konsumsi (Y). Ketika sudah diperoleh model yang fit antara pendapatan dengan konsumsi, maka kita dapat memprediksi berapa tingkat konsumsi masyarakat ketika kita sudah mengetahui pendapatan masyarakat.
2. Mengukur pengaruh variabel X terhadap variabel Y. Misalkan kita memiliki satu serial data variabel Y, melalui analisis regresi linier sederhana kita dapat membuat model variabel-variabel yang memiliki pengaruh terhadap variabel Y. Hubungan antara variabel dalam analisis regresi bersifat kausalitas atau sebab akibat. Berbeda halnya dengan analisis korelasi yang hanya melihat hubungan asosiatif tanpa mengetahui apa variabel yang menjadi sebab dan apa variabel yang menjadi akibat.
Model regresi linier sederhana yang baik harus memenuhi asumsi-asumsi berikut:
1. Eksogenitas yang lemah, kita harus memahami secara mendasar sebelum menggunakan analisis regresi bahwa analisis ini mensyaratkan bahwa variabel X bersifat fixed atau tetap, sementara variabel Y bersifat random. Maksudnya adalah satu nilai variabel X akan memprediksi variabel Y sehingga ada kemungkinan beberapa variabel Y. dengan demikian harus ada nilai error atau kesalahan pada variabel Y. Sebagai contoh ketika pendapatan (X) seseorang sebesar Rp 1 juta rupiah, maka pengeluarannya bisa saja, Rp 500 ribu, Rp 600 ribu, Rp 700 ribu dan seterusnya.
2. Linieritas, seperti sudah dijelaskan sebelumnya bahwa model analisis regresi bersifat linier. artinya kenaikan variabel X harus diikuti secara proporsional oleh kenaikan variabel Y. Jika dalam pengujian linieritas tidak terpenuhi, maka kita dapat melakukan transformasi data atau menggunakan model kuadratik, eksponensial atau model lainnya yang sesuai dengan pola hubungan non-linier.
3. Varians error yang konstan, ini menjelaskan bahwa varians error atau varians residual yang tidak berubah-ubah pada respon yang berbeda. asumsi ini lebih dikenal dengan asumsi homoskedastisitas. Mengapa varians error perlu konstan? karena jika konstan maka variabel error dapat membentuk model sendiri dan mengganggu model. Oleh karena itu, penanggulangan permasalahan heteroskedastisitas/non-homoskedastisitas dapat diatasi dengan menambahkan model varians error ke dalam model atau model ARCH/GARCH.
4. Autokorelasi untuk data time series, jika kita menggunakan analisis regresi sederhana untuk data time series atau data yang disusun berdasarkan urutan waktu, maka ada satu asumsi yang harus dipenuhi yaitu asumsi autokorelasi. Asumsi ini melihat pengaruh variabel lag waktu sebelumnya terhadap variabel Y. Jika ada gangguan autokorelasi artinya ada pengaruh variabel lag waktu sebelumnya terhadap variabel Y. sebagai contoh, model kenaikan harga BBM terhadap inflasi, jika ditemukan atukorelasi artinya terdapat pengaruh lag waktu terhadap inflasi. Artinya inflasi hari ini atau bulan ini bukan dipengaruhi oleh kenaikan BBM hari ini namun dipengaruhi oleh kenaikan BBM sebelumnya (satu hari atau satu bulan tergantung data yang dikumpulkan).
- Topik 14 : Uji Validitas dan Reliabilitas dan Regresi dengan SPSS
Topik 14 : Uji Validitas dan Reliabilitas dan Regresi dengan SPSS
Uji Validitas dan Reliabilitas dan Regresi dengan SPSS
- Topik 15: Latihan Soal
Topik 15: Latihan Soal
Latihan Soal
Lihat Sub Topik 1
Sub Topik 1: Latihan Soal Page
- Topik 16 : UAS
Topik 16 : UAS
UAS
Kerjakan soal pada sub topik